Usando OpenId Connect com Confluent Cloud
- pedrobusko
- 31 de ago. de 2023
- 3 min de leitura
Este é um artigo traduzido originalmente publicado no blog do Brice Leporini: "Using OpenId Connect with Confluent Cloud".

Espero que você já tenha lido minha postagem anterior sobre o recurso que foi adicionado no Kafka 3.1 para autenticar aplicativos usando um provedor de identidade OpenId Connect externo. Agora você também pode fazer o mesmo com o Confluent Cloud . Inicialmente, a única maneira de autenticar aplicativos era usar chaves de API e segredos gerenciados no Confluent Cloud, mas oferecer a capacidade de gerenciar centralmente contas, credenciais e fluxos de autenticação em um único provedor de identidade é uma expectativa comum em muitas organizações.

Para configurá-lo, é bastante fácil e consiste em duas etapas. Primeiro, você precisa declarar um novo provedor de identidade para sua organização do Confluent Cloud. O Azure e o Okta estão completamente integrados, mas vamos nos concentrar no OpenId Connect padrão. Uma coisa boa com o OIDC é que esse padrão é completamente detectável, por exemplo, você pode descarregar livremente a configuração do serviço Google OIDC:
$ curl https://accounts.google.com/.well-known/openid-configuration
{"issuer": "https://accounts.google.com",
"authorization_endpoint": "https://accounts.google.com/o/oauth2/v2/auth",
"device_authorization_endpoint": "https://oauth2.googleapis.com/device/code",
"token_endpoint": "https://oauth2.googleapis.com/token",
"userinfo_endpoint": "https://openidconnect.googleapis.com/v1/userinfo",
"revocation_endpoint": "https://oauth2.googleapis.com/revoke",
"jwks_uri": "https://www.googleapis.com/oauth2/v3/certs",
[...]
}
.well-known/openid-configuration é um endpoint implementado por todos os provedores e esta é a única coisa que você precisa para definir o provedor de identidade no Confluent Cloud:
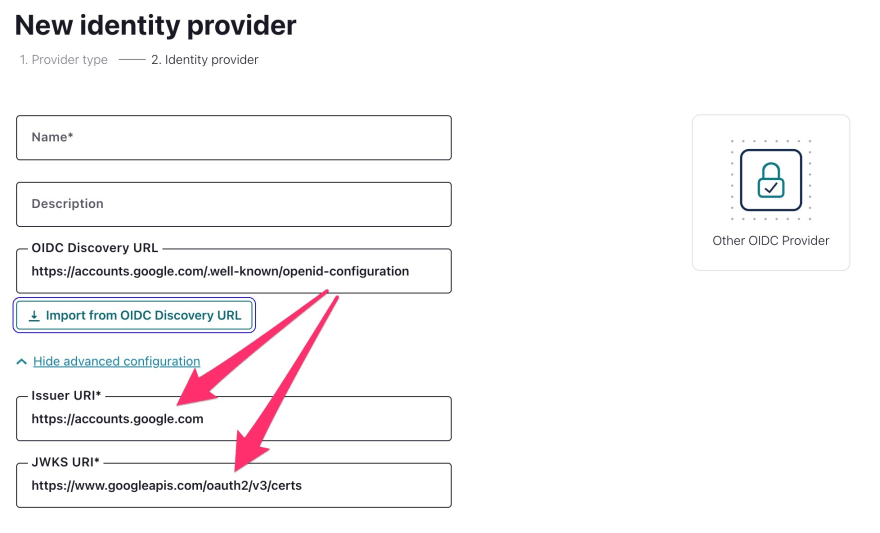
Como resultado, com a URL de configuração, o Confluent Cloud pode coletar automaticamente o URI do emissor, mas mais importante, o JWKS, que fornece as chaves públicas para verificar os JWTs.
A segunda etapa é declarar um pool de identidades. Na verdade, é uma forma de definir como os tokens JWT emitidos pelo IDP são qualificados para serem autenticados no serviço Confluent Cloud:

Para esta demonstração, vamos simplificar. O claims.subvalor padrão para o campo de declaração de identidade está perfeitamente correto, pois é uma declaração registrada para identificar o principal. Aqui está um exemplo de carga útil de um JWT (modificado, não realmente emitido pelo Google 😉):
{"iss": "https://accounts.google.com","sub": "dZJPsd9oVtAciRY8F5lHzk4yS0hfnBiE@clients","aud": "https://kafka.auth","iat": 1672817905,"exp": 1672904305,"azp": "dZJPsd9oVtAciRY8F5lHzk4yS0hfnBiE","scope": "scope","gty": "client-credentials"}Em seguida, vamos definir que todo JWT que vem com o https://kafka.authvalor na auddeclaração é válido. Observe que a declaração de público pode ser uma matriz de strings em vez de um único campo com valor. Esse valor é definido no IDP.
Para finalizar a criação, você precisa vincular papéis e recursos a esse novo pool de identidades, o que é uma operação normal para todo administrador do Confluent Cloud!
Agora vamos verificar se está funcionando com um consumidor Kafka burro. Graças ao assistente de Novo cliente, obter uma configuração básica para começar é fácil:

Mas você precisa ajustar um pouco para definir como o aplicativo Java deve solicitar o JWT para fornecer o Confluent Cloud, é quase como o que foi mostrado no meu post anterior , mas além disso você precisa definir a sonfiguração do JAAS com o ID lógico do cluster e o ID do pool de identidades:
sasl.mechanism=OAUTHBEARERsasl.login.callback.handler.class=org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandlersasl.login.connect.timeout.ms=15000sasl.oauthbearer.token.endpoint.url=https://oauth2.googleapis.com/tokensasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \
clientId="dZJPsd9oVtAciRY8F5lHzk4yS0hfnBiE" \
clientSecret="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" \
extension_logicalCluster="lkc-000000" \
extension_identityPoolId="pool-XXXXX" ;
Então você pode testar:
$ docker run --rm -ti -v $PWD:/work --workdir /work confluentinc/cp-kafka kafka-console-consumer --consumer.config config.properties --topic test --bootstrap-server pkc-xxxxxx.europe-west1.gcp.confluent.cloud:9092 --from-beginning[2023-01-04 12:17:49,565] WARN These configurations '[basic.auth.credentials.source, acks, schema.registry.url, basic.auth.user.info]' were supplied but are not used yet. (org.apache.kafka.clients.consumer.ConsumerConfig){"ordertime":1497014222380,"orderid":18,"itemid":"Item_184","address":{"city":"Mountain View","state":"CA","zipcode":94041}}{"ordertime":1497014222380,"orderid":18,"itemid":"Item_184","address":{"city":"Mountain View","state":"CA","zipcode":94041}}
^CProcessed a total of 2 messagesDê um sabor de automação...
Tudo isso foi configurado manualmente, usando interfaces gráficas de usuário e assistentes para guiá-lo gradualmente por esse processo, no entanto, a organização moderna requer uma maneira automatizada de provisionar recursos. Adivinhe, você tem várias opções para fazer isso com o Confluent Cloud. O nível baixo é usar a API REST do Confluent Cloud , mas é mais provável que você opte pela opção Terraform. Dessa forma, você tem uma abordagem real de infraestrutura como código e é completamente incorporável em uma definição de infraestrutura global. Portanto, sinta-se à vontade para ler a documentação do provedor Confluent Cloud Terraform e especialmente as seções sobre o provedor de identidade e sobre o pool de identidades .
Obviamente, tudo isso é apenas uma introdução inicial à integração do OIDC no Confluent Cloud e recomendo dar uma olhada na documentação abrangente .
Comments